Parsing XML in Rust: by hand & by macro
Lately I've been playing around with writing a feed reader in Rust. The two ubiquitous feed formats—RSS and Atom—are both XML-based, which means I've been writing a lot of code to go from XML to the actual Rust structs I can use in my code. This post will show how my parsing logic went from "boilerplate heavy, hand-written monstrosity" to just a single line of code using the power of macros.
I'm going to stick to a fairly high-level overview in this post (think "what are Rust macros and why would I use them,"
not "here are the intricacies of mixing proc_macro and proc_macro2"). I also assume that the reader has some
familiarity with Rust, but I don't think that's required to follow the main points. If you want the full gory details,
check out the source code.
Disclaimer: as you'll soon realize, I'm figuring this out as I go; don't treat this as an authoritative reference on style, structure, or… well, anything else really. Here's what I can offer though: just enough knowledge to be dangerous.
Setup
Let's say we're dealing with some XML that has a very simple structure, like the following:
<post>
<title>Mustache waxing tips</title>
<author>Guy Incognito</author>
</post>
We can very naturally represent that in Rust with a struct1:
struct Post {
title: String,
author: String,
}
The question we face is: how can we turn our XML snippet above into a concrete instance of Post?
Artisanal, handmade parser
Well, first things first: before we can think about the contents of our XML, we're going to need to convert the raw text
into the semantic XML elements it comprises. I don't have the appetite to write a full XML parser from scratch, so
instead let's leverage xml-rs. We'll start with a short program to acquaint
ourselves with its API:
use xml::reader::EventReader;
fn print_indent(indent: u8) {
for _ in 0..indent {
print!(" ");
}
}
fn print_xml(s: &str) {
use xml::reader::XmlEvent::*;
let reader = EventReader::from_str(s);
let mut indent = 0;
for event in reader {
match event {
Err(e) => println!("Saw an error: {}", e),
Ok(StartDocument { .. }) => println!("START OF DOCUMENT"),
Ok(StartElement { name, .. }) => {
print_indent(indent);
println!("Begin element <{}>", name);
indent += 2;
}
Ok(Characters(s)) => {
print_indent(indent);
println!("contents: '{}'", s);
}
Ok(EndElement { name, .. }) => {
indent -= 2;
print_indent(indent);
println!("End element <{}>", name);
}
Ok(Whitespace(_)) => (), // ignore whitespace (better: see xml::reader::ParserConfig)
Ok(EndDocument { .. }) => println!("END OF DOCUMENT"),
Ok(_) => println!("Saw an unrecognized event..."),
}
}
}
fn main() {
let input = "<post>
<title>Mustache waxing tips</title>
<author>Guy Incognito</author>
</post>";
print_xml(input);
}
Running that prints:
START OF DOCUMENT
Begin element <post>
Begin element <title>
contents: 'Mustache waxing tips'
End element <title>
Begin element <author>
contents: 'Guy Incognito'
End element <author>
End element <post>
END OF DOCUMENT
This seems pretty straightforward: StartElement and EndElement tags tell us what we're dealing with, and in our case
we just want to extract the contents of the Characters event between them for each field in our struct. I remember
enjoying messing around with finite-state machines in university; just for old times' sake, let's emulate one by
tracking what state we're in as we process the events:
use xml::reader::EventReader;
#[derive(Default)]
struct Post {
title: String,
author: String,
}
fn parse_post(s: &str) -> Post {
enum ParserState {
AwaitingPost,
BuildingPost,
AwaitingTitle,
AwaitingAuthor,
}
use xml::reader::XmlEvent::*;
use ParserState::*;
let reader = EventReader::from_str(s);
let mut post = Post::default();
let mut state = AwaitingPost;
for event in reader {
match (&state, event) {
(_, Err(e)) => println!("Saw an error: {}", e),
(AwaitingPost, Ok(StartElement { name, .. })) if name.local_name == "post" => {
state = BuildingPost;
}
(BuildingPost, Ok(StartElement { name, .. })) if name.local_name == "title" => {
state = AwaitingTitle;
}
(BuildingPost, Ok(StartElement { name, .. })) if name.local_name == "author" => {
state = AwaitingAuthor;
}
(AwaitingTitle, Ok(Characters(s))) => {
post.title = s;
}
(AwaitingAuthor, Ok(Characters(s))) => {
post.author = s;
}
(AwaitingTitle, Ok(EndElement { name, .. })) if name.local_name == "title" => {
state = BuildingPost;
}
(AwaitingAuthor, Ok(EndElement { name, .. })) if name.local_name == "author" => {
state = BuildingPost;
}
(_, Ok(_)) => (), // ignore other events
}
}
post
}
fn main() {
let input = "<post>
<title>Mustache waxing tips</title>
<author>Guy Incognito</author>
</post>";
let post = parse_post(input);
assert_eq!(post.title, "Mustache waxing tips");
assert_eq!(post.author, "Guy Incognito");
}
Let's break down some key points:
- We define a function
parse_postto extract aPostfrom an (XML-serialized)&str. Theassert_eq!calls confirm that thePostit produces has the title and author we expect. - As promised,
parse_posttracks its state internally and uses that to decide what to do next (see below for a diagram showing the key states & transitions). - If a match pattern like
(AwaitingPost, Ok(StartElement { name, .. })) if name.local_name == "post"is wrong, I don't want to be right. Sure, it's long, but we express so much, so clearly in this pattern: "if we're in stateAwaitingPostand we see a<post>element, run this code…" I adore structural pattern matching, and being able to check conditions on fields that we extract from nested patterns is simply *chef's kiss*. - Pros:
- Maybe it's just me, but I really like modelling this as a state machine. We define the semantically meaningful states for our parser, and the XML events we observe inform the transitions. That means we only need to reason in small, "local" steps, i.e. "if I'm in state X and observe event Y, what should I do?" Answering questions of that form is generally straightforward, and once we've pinned down those local details, the big picture just ends up working out.
- Cons:
- Even with only two fields, there's already some obvious repetition: we create effectively the same set of states &
transitions for
titleandauthor, just with different names. We could support new fields by updatingparse_post, but it would be a little onerous to do so. - We're being a little sloppy with our validation/error handling (e.g., we don't complain about a mismatched closing tag, even though it would mess us up). That's mostly for the sake of brevity here—we could better use/extend the parser states to signal descriptive errors in those cases (at the cost of adding some additional complexity).
- If a field is missing in our XML representation, the corresponding struct field retains its default value (from
Post::default()). That means we can't distinguish between "this field was missing in the original XML" and "the field was present, but it happened to be empty." We could better signal our intent by usingOption<T>in our struct fields.2
- Even with only two fields, there's already some obvious repetition: we create effectively the same set of states &
transitions for
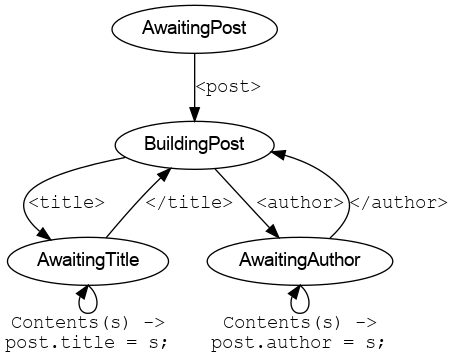
A graphical representation of the important states/transitions in our hand-written parser
Rise of the machines
I like the core design of our parser, but it's not very practical for my feed reader use case—those structs can have dozens of fields, making the repetitive boilerplate unreasonably onerous. But wait—isn't programming all about automating away boring, repetitive tasks? Since the transitions are so formulaic, can't we just write code to generate that other code for us?
Of course we can! And in Rust, macros are how we do just that. In fact, we've already seen an example. Take another look
at parse_post: we call the function Post::default(), but we haven't actually defined it
anywhere ourselves. From whence cometh this ghostly function? Well, notice how we annotated our struct definition with
#[derive(Default)]. That's us asking the compiler "hey—I know there's this
Default trait out there, and it has some methods I want
implemented for Post… but I really don't want to implement them myself. D'ya think maybe you could help me
out?" And thanks to a procedural macro behind the scenes, it can!
So, how do write our own macro? First, we should cover the two families of macros in Rust: declarative macros and procedural macros. In a declarative macro, we specify pattern(s) and their corresponding expansions. The compiler attempts to match our patterns against the macro arguments, and replaces them with the corresponding expansion. (We'll see an example of this later.) Procedural macros are more flexible and more complicated to write: rather than providing patterns for the compiler to match, a procedural macro receives a list of raw tokens3 and also returns a list of raw tokens—this provides a very general mechanism to inspect some user-provided code and generate other code in response.
One nice way to frame our problem conceptually is to start by defining a trait that expresses our desired behaviour. The function signature from our previous parser still seems to fit the bill, so let's create a trait with just that function:
// Recall that our parser above calls T::default(), then fills in the members
// one at a time, so we require that T implements Default
pub trait DeserializeXml: Default {
fn from_str(s: &str) -> Result<Self>;
}
What we'd like to be able to do now is to automatically generate an implementation for DeserializeXml for a given
struct. In Rust, we can do this with derive
macros, which are a type
of procedural macro. If you've ever used a templating language (like Jinja), that's how I like to think about this: we
need to define a template for the code we want to generate, and that template will get expanded with the struct for
which our derive macro is being called.4 To be very literal about it, here's what our from_str
implementation might look like if we actually did write it out as a Jinja template:
impl DeserializeXml for {{ struct.name }} {
fn from_str(s: &str) -> Result<Self> {
enum ParserState {
Awaiting_{{ struct.name }},
Building_{{ struct.name }},
{% for field in struct.fields %}
Awaiting_{{ field }},
{% endfor %}
}
use xml::reader::XmlEvent::*;
use ParserState::*;
let reader = EventReader::from_str(s);
let mut result = {{ struct.name }}::default();
let mut state = Awaiting_{{ struct.name }};
for event in reader {
match (&state, event) {
(_, Err(e)) => println!("Saw an error: {}", e),
(Awaiting_{{ struct.name }}, Ok(StartElement { name, .. })) if name.local_name == "{{ struct.name }}" => {
state = Building_{{ struct.name }};
}
{% for field in struct.fields %}
(Building_{{ struct.name }}, Ok(StartElement { name, .. })) if name.local_name == "{{ field }}" => {
state = Awaiting_{{ field }};
}
(Awaiting_{{ field }}, Ok(Characters(s))) => {
result.{{ field }} = s;
}
(Awaiting_{{ field }}, Ok(EndElement { name, .. })) if name.local_name == "{{ field }}" => {
state = Building_{{ struct.name }};
}
{% endfor %}
(_, Ok(_)) => (), // ignore other events
}
}
Ok(result)
}
}
If we were to expand that template with this…
{
"struct": {
"name": "post",
"fields": ["title", "author"]
}
}
…we'd end up with basically the same from_str implementation that we wrote by hand before!
Of course, procedural macros aren't actually written as Jinja templates. You can see the nitty-gritty of my
implementation in this file
(warning: ugly and hacky code!), but honestly, I don't think it is particularly instructive. Instead, let me share one
(annotated & edited) snippet to show we're not so far off from the template version above. (Note: in this snippet,
anything in a quote! block will be emitted as literal Rust code; furthermore, #ident within a quote! block means "replace
#ident with the value of the variable ident before generating the code.")
// The heart of our macro: for each field in the struct, generate the relevant match arms
for field in &named.named { // named.named is the named fields of our struct
let field_name = field.ident.as_ref().unwrap();
// I.e. if the field is type Vec<T>, we want inner_type to be T
let inner_type = extract_inner_vec_type(&field.ty);
let mut tag_name = match inner_type {
// By default, assume that struct `Post` corresponds to XML tag `<post>`
None => field_name.to_string().to_ascii_lowercase(),
Some(inner_type) => inner_type.to_string().to_ascii_lowercase(),
};
// To parse the field, we make a recursive call (this field could be a struct itself!)
// `from_reader` is similar to the `from_str` we defined in earlier examples
let assignment_stmt = match inner_type {
None => quote! {
result.#field_name = DeserializeXml::from_reader(reader)?;
},
// If the associated struct field is a Vec, we need to push (not just assign)
Some(_) => quote! {
result.#field_name.push(DeserializeXml::from_reader(reader)?);
},
};
// Same match pattern idea as before
let match_body_case = quote! {
(BuildingStruct, Ok(StartElement { name, .. })) if name.local_name == #tag_name && name.prefix.is_none() => {
#assignment_stmt
}
};
match_body.push(match_body_case);
}
Our reward
We've gone through all the effort of defining our own trait and writing a procedural macro that can automatically
generate an implementation of said trait. Was it worth it? Well, here's an example of what our macro can do for us now
(don't worry about those #[deserialize_xml(...)] sections; we'll cover those
below):
use deserialize_xml::DeserializeXml;
#[derive(Default, Debug, DeserializeXml)]
// This attribute indicates we should parse this struct upon encountering an <item> tag
#[deserialize_xml(tag = "item")]
struct Post {
title: String,
author: String,
}
#[derive(Default, Debug, DeserializeXml)]
struct Channel {
title: String,
// This allows us to use an idiomatic name for the
// struct member instead of the raw tag name
#[deserialize_xml(tag = "lastUpdated")]
last_updated: String,
ttl: u32,
// (unfortunately, we need to repeat `tag = "item"` here for now)
#[deserialize_xml(tag = "item")]
entries: Vec<StringOnly>,
}
let input = r#"<channel>
<title>test channel please ignore</title>
<lastUpdated>2022-09-22</lastUpdated>
<ttl>3600</ttl>
<item><title>Article 1</title><author>Guy</author></item>
<item><title>Article 2</title><author>Dudette</author></item>
</channel>"#;
let result = Channel::from_str(input).unwrap();
assert_eq!(result.title, "test channel please ignore");
assert_eq!(result.last_updated, "2022-09-22");
assert_eq!(result.ttl, 3600);
assert_eq!(result.entries.len(), 2);
assert_eq!(result.entries[0].title, "Article 1");
assert_eq!(result.entries[0].author, "Guy");
assert_eq!(result.entries[1].title, "Article 2");
assert_eq!(result.entries[1].author, "Dudette");
We've successfully parsed a Vec of struct within another struct from XML, and all we had to do was add a couple of
#[derive(DeserializeXml)] calls—that seems pretty good to me. 😎
Extras
The other flavour of macros: declarative
If you were paying attention, you might've spotted a problem in the procedural macro snippet above. To
parse a struct member, we make a recursive call to DeserializeXml::from_reader. That makes sense if our struct's field
is a struct itself (we could call our macro on both the outer and inner structs to ensure DeserializeXml::from_reader
is implemented for both), but eventually we're going to want to parse something simple—say a String or u8.
What happens then? It doesn't seem like that will compile, since there's no implementation of
DeserializeXml::from_reader for String. However, since these types are obvious "base cases" that presumably will
always be handled the same way, my crate provides implementations for those specific types.
Let's take a closer look at what such an implementation should look like for u8. Conceptually, it's pretty
straightforward: we just need to extract the contents of the Characters event (like before); the only difference is
that now we also need to parse that string to a u8 before returning. Being a little bit lax about our error handling,
the result might look something like this:
impl DeserializeXml for u8 {
fn from_reader<R: Read>(reader: &mut Peekable<::xml::reader::Events<R>>) -> Result<Self> {
use ::xml::reader::XmlEvent::*;
reader.next(); // TODO: assert this is a StartElement; raise error if not
let result = match reader.next().unwrap() {
Ok(Characters(s)) => Ok(s.parse::<u8>()?), // String -> u8 happens here
Ok(event) => {
let msg = format!("when parsing u8: expected characters, but saw {:?}", event);
Err(Error::new(msg))?
},
Err(e) => Err(e)?,
};
reader.next(); // TODO: assert this is an EndElement; raise error if not
result
}
}
That works just fine, so we can just copy-paste-find-replace it for i8. And u16, and i16. But by the time we get
to the 32s, there should be a nagging voice in back of your mind: "this whole project has been about automating away
boilerplate code—why are we repeating what is effectively the same implementation over and over again?"
We might naturally reach once again for derive macros, but they're not really a good fit here. There's no struct for
us to annotate with our #[derive]—instead, we just want some simple way to repeat our implementation for a
variety of types. Fortunately, declarative macros let us do just that!
For more details, I'll direct you to the Rust Book, but
suffice it to say, declarative macros look much more like regular match statements: we provide one or more patterns
and their corresponding code; our macro will match its arguments against those patterns and emit the corresponding code.
// Define our declarative macro...
macro_rules! generate_numeric_impl {
// Here's our pattern: we're expecting to receive one argument, which will
// itself be a type (e.g., u8)--we can refer to that argument later as $type
($type:ty) => {
// Here's our implementation: the same as before, but using $type, not u8
impl DeserializeXml for $type {
fn from_reader<R: Read>(reader: &mut Peekable<::xml::reader::Events<R>>) -> Result<Self> {
use ::xml::reader::XmlEvent::*;
let unexpected_end_msg = "XML stream ended unexpectedly";
let msg_prefix = "when parsing numeric type:";
reader.next(); // TODO: assert this is a StartElement; raise error if not
let result = match reader.next() {
Some(Ok(Characters(s))) => Ok(s.parse::<$type>()?),
Some(Ok(event)) => {
let msg = format!("{} expected characters, but saw {:?}", msg_prefix, event);
Err(Error::new(msg))?
},
Some(Err(e)) => Err(e)?,
None => Err(Error::new(unexpected_end_msg.to_string()))?,
};
reader.next(); // TODO: assert this is an EndElement; raise error if not
result
}
}
};
}
// ...then use it to generate an implementation for each numeric type
generate_numeric_impl!(u8);
generate_numeric_impl!(i8);
generate_numeric_impl!(u16);
generate_numeric_impl!(i16);
generate_numeric_impl!(u32);
generate_numeric_impl!(i32);
generate_numeric_impl!(u64);
generate_numeric_impl!(i64);
generate_numeric_impl!(u128);
generate_numeric_impl!(i128);
generate_numeric_impl!(usize);
generate_numeric_impl!(isize);
Now we only have one place to maintain all our logic, and supporting another type of the same "family" is as simple as adding one line. Neat!
Adding more functionality with attributes
Another weakness of the macro snippet we looked at earlier is that it assumes the XML tag
corresponding to
your struct will just be the the struct's name in lowercase—e.g., for a struct named Post, it will only look for
<post> tags in the XML. Of course, that won't always be the case, so it would be nice if the end user could specify an
override somehow; something like "I know this struct is named Post, but in my XML it's represented by <entry> tags."
(And likewise for the fields of the struct, too.)
We can support this kind of functionality in our macro by adding attributes. Attributes are basically structured annotations the end user can add to their code; our macro will be able to examine those annotations and change its behaviour accordingly. Borrowing from our example before, here's what an attribute to support custom tag specification could look like:
struct Channel {
title: String,
#[deserialize_xml(tag = "lastUpdated")] // here's our attribute
// The field is named `last_updated`, but the corresponding tag is `<lastUpdated>`
last_updated: String,
}
And here's how our macro might react to seeing that attribute (you can see the full code in
deserialize_xml_derive/src/lib.rs):
// (previously: tag_name = field_name.to_string().to_ascii_lowercase();)
// Each field in our struct could have zero or more attributes
for raw_attr in &field.attrs {
for parsed_attr in parse_attr(raw_attr) {
match parsed_attr {
// We only support one attribute--if the user provided it,
// use that value as the tag name while parsing the XML
Attr::Tag(s) => { tag_name = s; },
}
}
}
Of course, this is only scratching the surface—the crate clap is a good
example of just how far you can take attributes.
Conclusion
I hope this post has given some understanding of—and enthusiasm for—macros. They're not the right tool for every job, but they're extremely useful to have in your toolbelt. (And fun!)
If you're interested in further exploring the deserialize_xml example, you can check out the source
code or the
documentation. I should probably also point out that the
real ecosystem to do this sort of thing in Rust is serde—it defines Serialize and
Deserialize traits, which other crates have then implemented for a wide range of formats.
Happy macro-ing!
Yeah, we're going to stick with String and not bother with &str; this isn't an article about lifetimes. Sorry to disappoint.
But what if those fields aren't really optional for our struct—e.g., assume our Post must have a title;
how can we handle that? One solution that I'm partial to is to have two structs, Post and PostData, and provide an
implementation of TryFrom<PostData> for Post.PostData
is a "plain old data" struct that simply holds an Option<T> version of each field in Post. When we want to extract a
Post from XML, we start by parsing the XML to a PostData struct. (Since all of the PostData fields are
Option<T>, it's fine if some are missing at that point.) To get an actual Post instance, we need to call
Post::try_from(post_data)—which is exactly where we can put any necessary validation logic (e.g., Post::title is required, but PostData::title is None). This approach ensures we never create an invalid Post, but without unduly
complicating our XML parsing.
Technically, a TokenStream.
I know, this sounds exactly like how I described declarative (not procedural!) macros before.
Declarative macros use a match-like syntax, which can make it difficult to express complex logic. Since procedural
macros operate on the TokenStream directly, there's no such limitation. Personally, I still find "(complicated)
template expansion" to be a good mental model of what you can do with them.